The Read Write Splitter at ZipRecruiter
At my talk at YAPC a few weeks ago I discussed some technology at ZipRecruiter that’s called the read/write splitter (or more often the rwsplitter or simply the splitter.) I have intended to write about this for a long time and the fact that I was unable to refer to a blog post for the talk finally convinced me that I must.
🔗 The Read/Write Splitter
The Read/Write Splitter is some code that is integrated at various places in our stack that allows us to shed a significant amount of our queries to read replicas. The main improvement we get over more typical solutions is that our users (who are both end-users and most of our engineers) are unaware of the reader lag. Someone can write normal code at ZipRecruiter without having to think about distributed systems. Nice.
ZipRecruiter is not the first company to invent this kind of technology. At one point I was in a meeting (after we’d written the splitter) where Percona was trying to sell us their splitter, which is implemented as a MySQL proxy and some plugins, I think written in C++. You could do clever things like split based on the actual query etc. What makes ours different (at least from that one) is that it is integrated with the actual application.
A brief aside about terms: I understand that the normal term for the writer database and read follower databases are actually master and slaves. The obvious fault of these terms is sufficient for me to abandon them. On top of that the old terms are technically inaccurate. The implementation of any kind of replication tends to be much closer to some kind of following than some kind of slavery.
There are two components to the splitter. The first is the actual ORM level logic, which is fairly straightforward. At the storage layer (which, in DBIx::Class is a completely separate object) we intercept the various methods that do reads or writes and dispatch the appropriately. Here’s the list, just so that it’s clear:
insert => 'rw',
_insert_bulk => 'rw',
update => 'rw',
delete => 'rw',
select => 'ro',
select_single => 'ro',
_select => 'ro',
# these aren't for sure a write, but once one of these has started it's
# too late and we have to assume it could be
dbh_do => 'rw',
txn_begin => 'rw',
connect_call_do_sql => 'rw',
disconnect_call_do_sql => 'rw',When a write occurs we store the timestamp of the write. Keep that in mind for the second component. After the write happens we continue to use the write handle until the splitter is told to switch back to a reader, or until enough time has passed that we believe our changes have been replicated down to the readers. All of this code is research and fairly basic bookkeeping. Ours is about 400 lines of perl, most of which is simple accessors.
The most perilous part is the estimation of the lag. If you overestimate you can send too many queries to the writer and eventually cause an outage. If you underestimate you can serve stale data, or worse, accidentally read stale data and feed it back into the writer.
The other component could be considered the “userland” storage of the time of the last write. In my talk I mentioned that we have a fairly basic Catalyst plugin that simply stores the last write time in a cookie. A request always starts at the readers, and after the cookie is read may switch to the writer. So if a user last did a write five minutes ago, all of their interactions will be with the read replicas. Note that the migration from writer to reader (or reader to writer) at the start of a request was at one point really tricky to get right because it happened so early in the process.
We have another userland component for one of our batch systems. This system, called Perform Queued Tasks, is a fairly standard system that pulls tasks off of a queue and handles them in a fork. The idea is to take advantage of the copy-on-write memory stuff. Anyway, there is a special splitter role for this system. When the task manager pulls a task off of the queue, it looks at when the task was inserted and checks to see if the reads replicas would be consistent with respect to queue insertion time. If they are not up to date, we simply put the item back on the queue with a delay. If the read replicas are up to date we process the task.
🔗 Pedigree and Other Ideas
The read/write splitter was a strawman that Aaron Hopkins threw out over drinks to our CTO, Craig Ogg. I built the original version, which didn’t work, but did override a lot of the correct methods at the storage layer. Aran Deltac (aka bluefeet) implemented (and mostly maintains) the current version. Geoff Begen implemented the Perform Queued Task splitter integration.
When I originally did the work, I did a lot of spitballing with my friend Peter Rabbitson. I had originally hoped to build it at the DBI layer, because that would, in theory, be simpler and more reliable. The problem is that for DBI I would have to have a database handle that could return statement handles for separate connections, maintaining a higher level session awareness than DBI was built for. While I honestly do not like doing this at the ORM layer, it was by far the most natural.
We have pretty good monitoring of the splitter. Here is a graph from our monitoring system that shows the splitter in action:
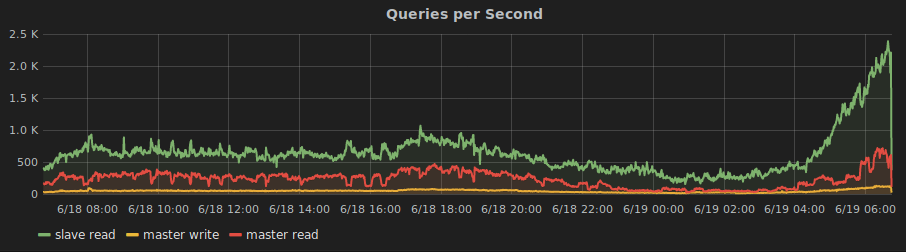
Despite the good monitoring, we tend to only discover bugs in the splitter after they go to production. Or maybe that’s selection bias and I only tend to notice once they get there. Either way, bugs do sometimes creep in.
I have been asked if we would be willing to Open Source the splitter. I think we would be willing to publish the code, but it’s not easy to use. In typical DBIC extensions you simply opt in to a given component with one line of code and however many are needed to configure it. With this, you end up needing to create either a completely parallel set of subclasses for the DBIC storage classes, or you have to do runtime role application. Both of these options are, in my mind, gross.
bluefeet tells me that he hopes to Open Source the Splitter, and potentially at the same time migrate the ORM component down into a DBI component directly. I think that would be a great move as it would simplify the installation greatly, though I would have started there if I had figured out how.
(The following includes affiliate links.)
Given that this article is mostly about Perl based software, and targetted
towards fairly advanced users, I will again take the opportunity to recommend
Higher-Order Perl.
The book really explains functional programming in a way that is interesting and
not incredibly painful for the average programmer.
Similarly, the
SRE book provides a great overview of this kind of engineering work in
general. For help on distributed systems you may need to go further, but this
would be a great first step.
If you're interested in being notified when new posts are published, you can subscribe here; you'll get an email once a week at the most.